Measuring success and analyzing results
This article will help you to:
- Gather sufficient data before deciding to end an experiment.
- Interpret the results of winning, losing, and inconclusive experiments.
Once you’ve started your experiment, you can view the results in the Creative Experiments Detail view. While you can start checking the results immediately, we recommend waiting at least two weeks to receive data before drawing any conclusions. You must leave your experiment running long enough to collect sufficient data to have a high level of confidence in the results.
Find the experiment details pageDirect link to Find the experiment details page
- In One Platform, click on your account on the Home page. Then go to the Campaigns > Experiments page from the left navigation menu.
- Locate or search for your experiment in the Overview list.
- Click on the experiment name to view the Details page.
In the top summary card you will find the following:
- Experiment name and hypothesis
- Options to end the experiment
- The number of days running
- Audience targeted in the experiment
For more information about the experiment settings or to edit allocations click Settings.
Below the top summary card, you will see the results for the experiment. As your experiment runs, you can monitor and compare its performance against your original creative. By looking at these results, you can see whether your results are significant and reliable. We recommend that you run your experiment until at least one variant has a 95% probability to beat the original baseline variant.
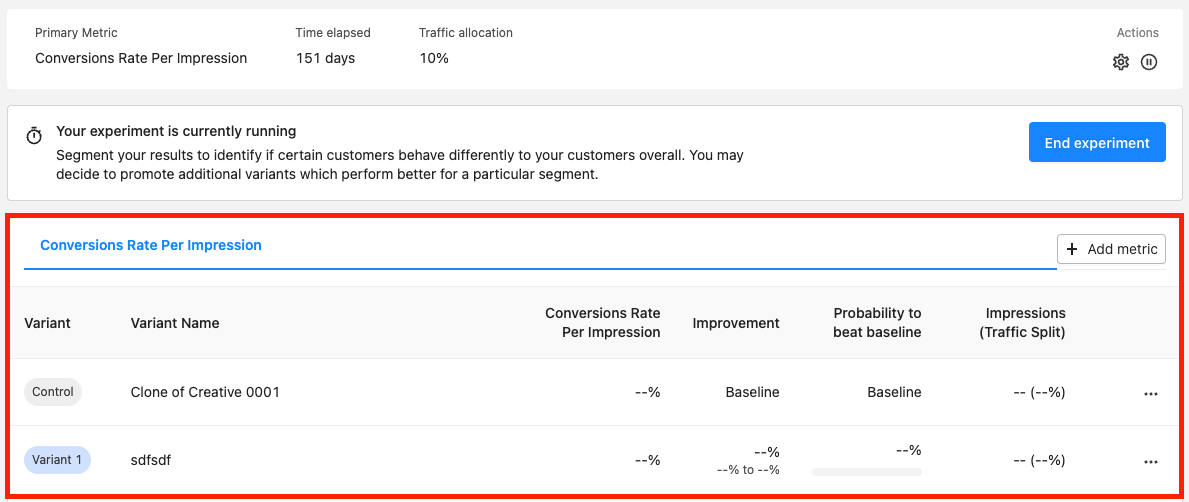
Rokt recommends you run your experiment until at least one variant has a 95% probability (or less than 5%) to beat the original baseline variant.
Interpreting your experiment resultsDirect link to Interpreting your experiment results
At the top of the results table, you will see the selected Metric. This Metric is used to calculate the probability of each variant to beat the original baseline variant. You may also want to view results for each variant against other metrics. Additional metrics help to identify potential unintended impacts on the experience.
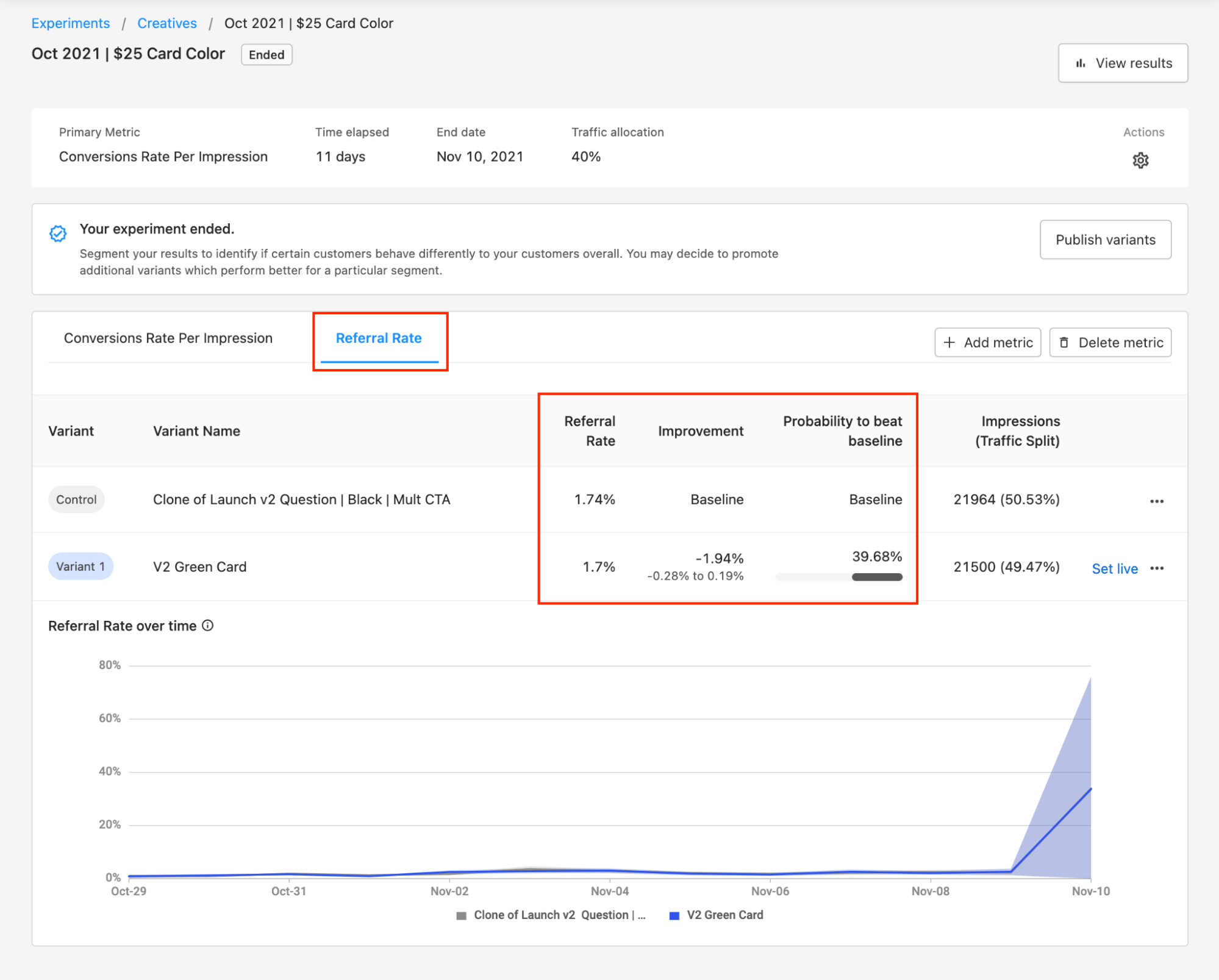
You can view other metrics by clicking + Add metric at the top of the results table. You can then choose the additional metrics you would like to view and click Save. To remove metrics you no longer want to view click Delete metric.
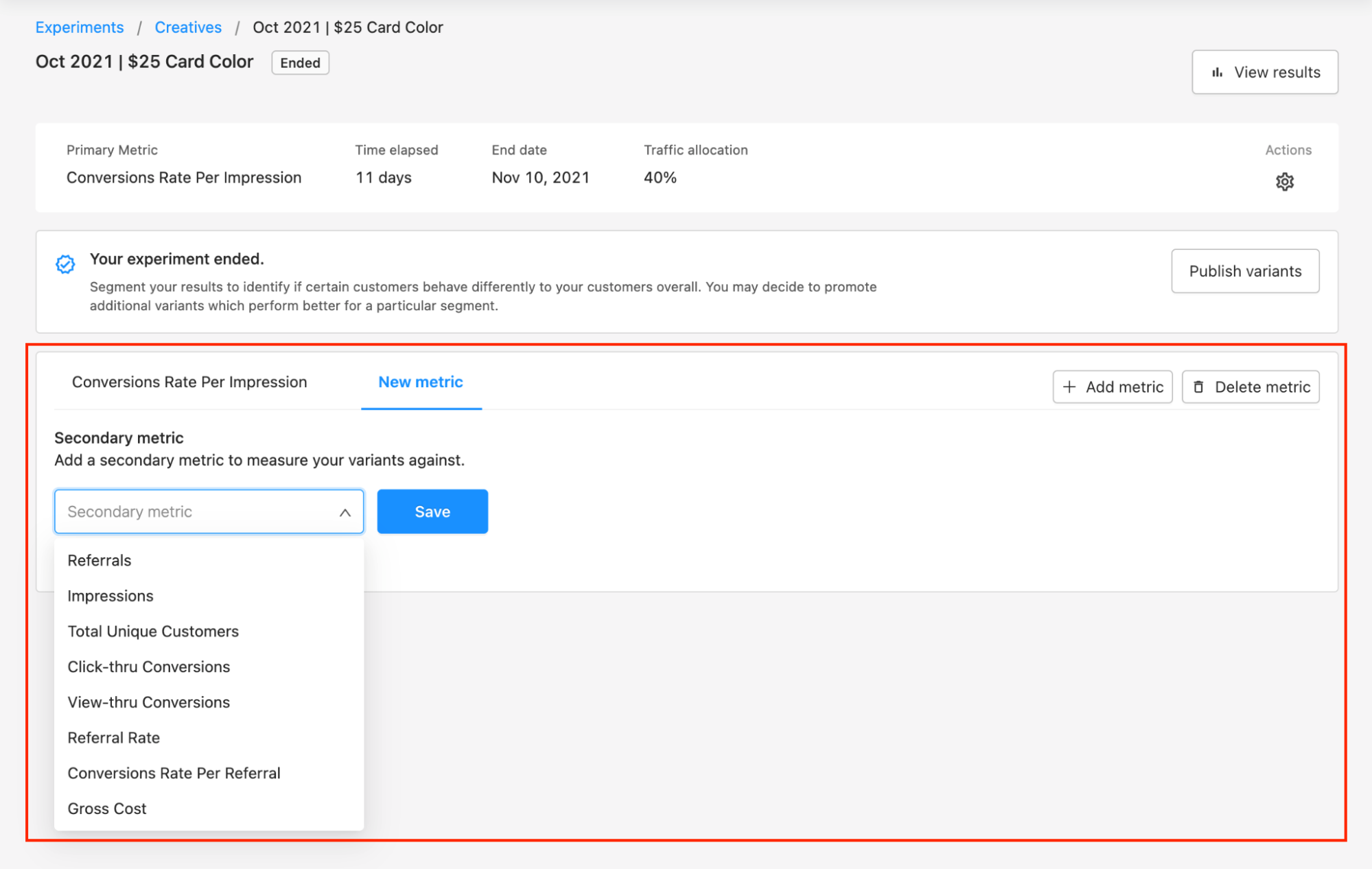
We generally recommend evaluating all secondary metrics to look for warnings that you’re negatively impacting other metrics.
ImprovementDirect link to Improvement
This metric measures the relative difference in performance between the test variants and the original for the selected metric. Use the tabs at the top of the results table to toggle between metrics.
Probability to beat baselineDirect link to Probability to beat baseline
This metric shows the probability that a variant is going to perform better than the baseline variant. If a variant beats the original by more than 95%, then the result is likely to be reliable and you can select it as the winner. It is possible to have more than one variant which beats the baseline.
We recommend waiting until the probability to beat baseline reaches 95% before deploying an experimental variant. Deploying earlier is possible, but risky because you'll be working with incomplete data.
Credible intervalDirect link to Credible interval
The credible interval measures uncertainty around improvement and displays a range of values where the performance for the selected metric actually lies. Below your experiment's data and analysis is a graph showing the credible interval for each of your variants. This visualizes how your variants have performed to date against the metric selected in your results table. You can see which metric has been selected by looking at the graph title.
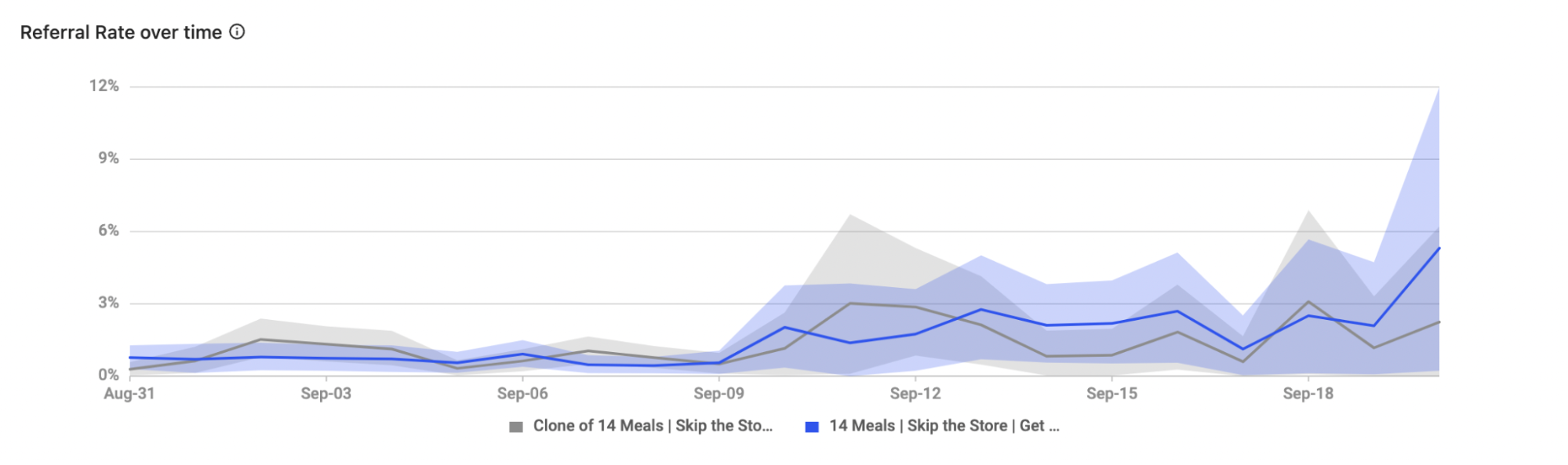
The graph starts out wide, indicating greater uncertainty of each variant’s performance. As the experiment collects more data over time, the interval narrows to show that certainty is increasing. Look for minimal or no overlap between the different lines (variants) on you graph to have greater confidence in your experiment results.
Deciding to call an experimentDirect link to Deciding to call an experiment
We recommend following a couple of rules when interpreting your experiment results and deciding to end the experiment.
- Wait until the experiment has been running for at least two weeks. This is to ensure the experiment has been running long enough to gather enough data.
- Take time to analyze the results and learn about your customers. The deeper you dive into the results and more time spent interpreting the data, the more you will be able to learn about your customers beyond which variants win and lose overall.
What do you do when you have a winner?Direct link to What do you do when you have a winner?
There are a number of potential scenarios when it comes to identifying the best performing variant or variants in your experiment.
-
The original is the winner. It’s possible that all of your experimental variants perform worse than the original baseline variant (all have <95% probability to beat baseline). In this situation it is better to leave your current experience live and end the experiment. The outcome is unlikely to change and your time would be better spent on a new experiment.
Do note that this is not a bad result or failed experiment! You’ve learned valuable information about how your customers behave which can be leveraged for future tests.
-
A specific variant is the winner. There is enough data to conclude that one of your variants outperforms the original for your primary success metric (i.e. a specific variant has 95% or higher probability to beat baseline). It’s safe to end the experiment and promote this variant to run as a standalone variant on your page. You may want to pause or remove the original variant if the experiment results show that the test variant performs better. If you prefer a slower transition and don’t want to pause or remove the original variant, Rokt’s machine learning algorithm will learn over time and show the best option for each customer.
-
Multiple variants beat the original. You may find that more than one of your test variants perform better than the original (i.e. multiple variants have 95% or higher probability to beat baseline). Once there is enough data to conclude that some of your variants perform better than the original, you should have enough data to conclude which is the absolute best. You can choose to promote only the variant with the highest probability to beat baseline, or multiple variants and leave it up to Rokt’s machine learning to determine which is the best option to show each customer.